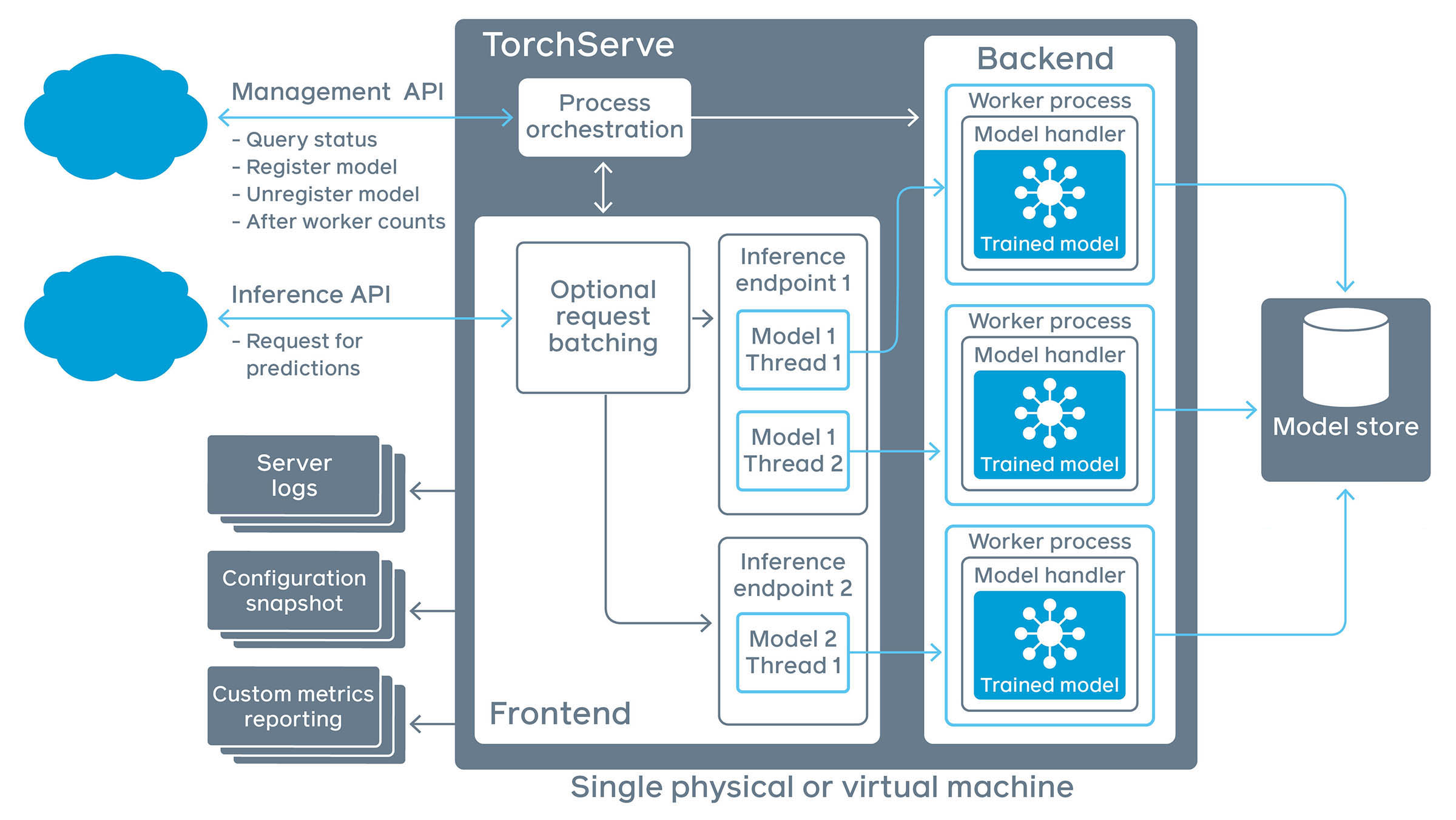
torchserve模型服务
optmization strategies
基本处理单元
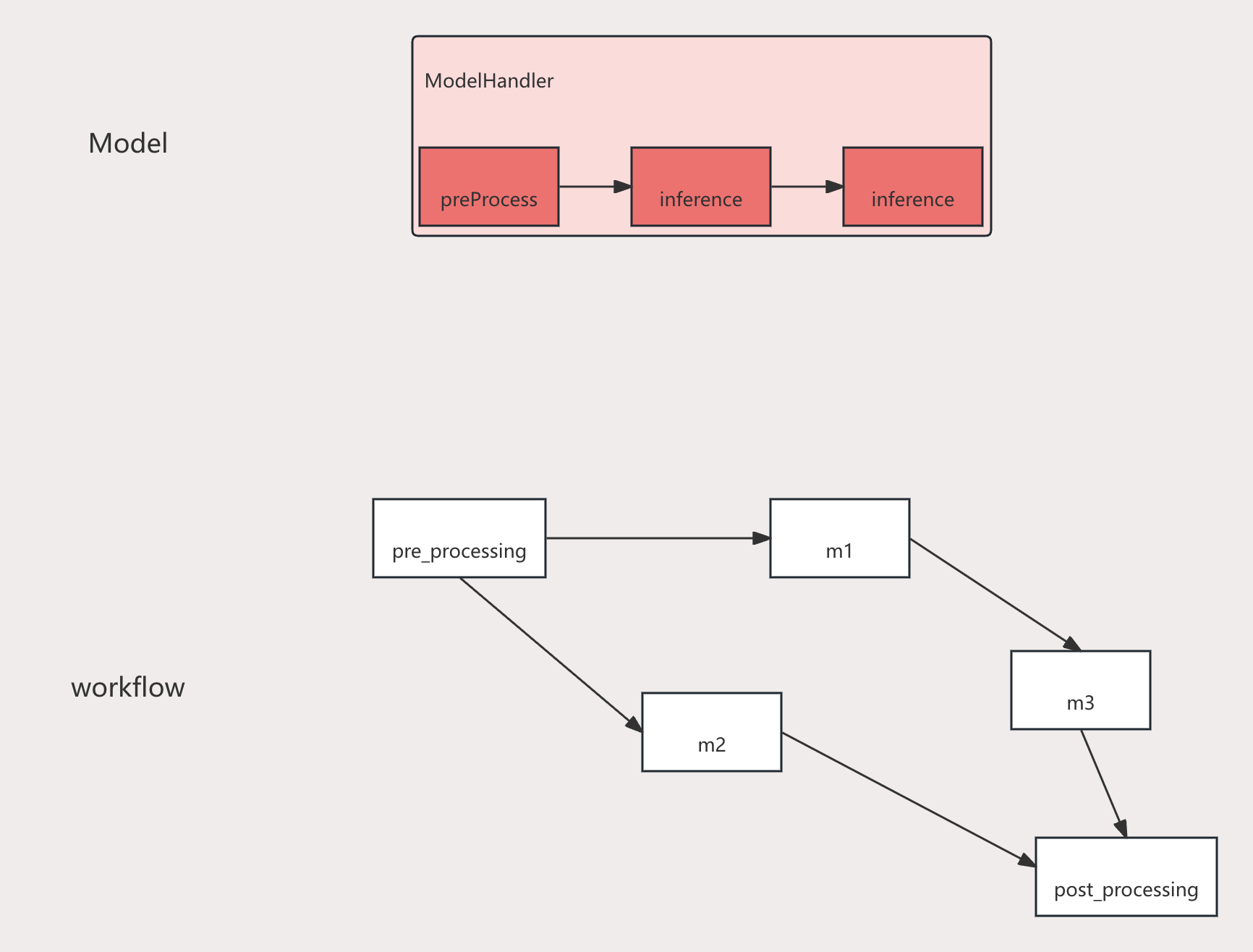
Model对应内部是一个Handler,包含preProcessing,inference和postProcess三部分。
workflow是一个有向无环图,每个节点代表一个处理任务;上图显示整个流程包含前后处理以及三个模型节点。
models:
#global model params
min-workers: 1
max-workers: 4
batch-size: 3
max-batch-delay : 5000
retry-attempts : 3
timeout-ms : 5000
m1:
url : model1.mar #local or public URI
min-workers: 1 #override the global params
max-workers: 2
batch-size: 4
m2:
url : model2.mar
m3:
url : model3.mar
batch-size: 3
m4:
url : model4.mar
dag:
pre_processing : [m1]
m1 : [m2]
m2 : [m3]
m3 : [m4]
m4 : [postprocessing]
在workflow配置中,我们不仅可以设置工作流,还可以设置model节点的worker数量、输入batch-size大小,处理延迟,重试次数等
这里的worker对应一个线程,多个线程会运行多个model实例
Torchserve默认运行在单个JVM进程中,所有的模型加载和处理都在此进程中完成;每个workflow的节点会通过线程池处理并发请求
优化策略
并发度
这里涉及:
- 每个模型的worker数量
- 每个mdoel可以设置的GPU数量
单GPU上,不推荐通过调大worker数量来增加推理吞吐量。因为多线程模型实例,在GPU上会是顺序执行,不会是真正的多模型并行执行。
当然,如果模型前后处理也是耗时的任务,那么通过多workder可以拆分requests,并发执行前后处理,降低单worker的工作负载,提高吞吐。 如下图所示:
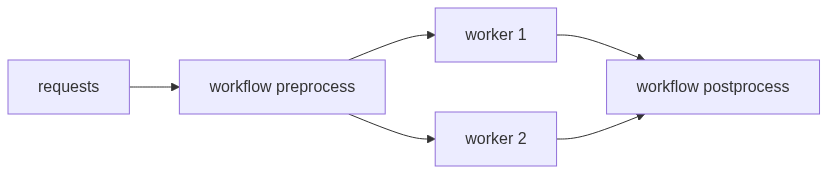
多GPU,通过多worker可以将模型实例分布在不同的GPU上,提高吞吐量的同时降低延迟
Micro-batching
该机制主要工作在Model层级
适用场景:
requests数量源源不断且数量较多时,为了提高系统吞吐
工作示意图如下:
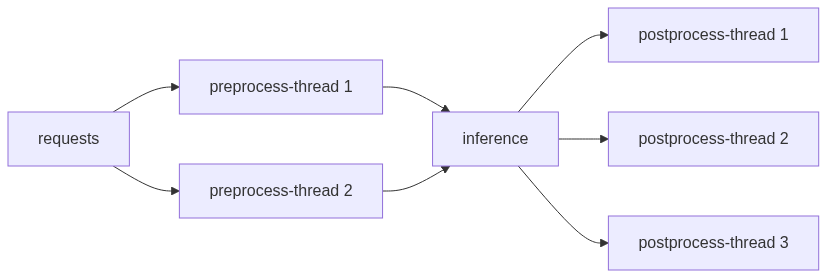
可以将输入的requests想象成一个request流,preprocess、inference和postprocess对应流水线上的三个环节。
Frontend会积聚request为较大的一个batch,然后发送至backend,在backend再拆分成多个micro-batch来处理。
当inference工作时,preprocess和postprocess也在进行处理,同时preprocess和postprocess支持并发处理。这样尽管三者存在依赖关系,流水线处理策略可以使得三个任务可以在时间上overlap,提高系统吞吐量。
参考配置如下:
batchSize: 32 #backend接收的batch大小
micro_batching:
micro_batch_size: 4 #拆分的micro-batch大小
parallelism:
preprocess: 2 #预处理的线程数量
inference: 1
postprocess: 2 #后处理线程的数量
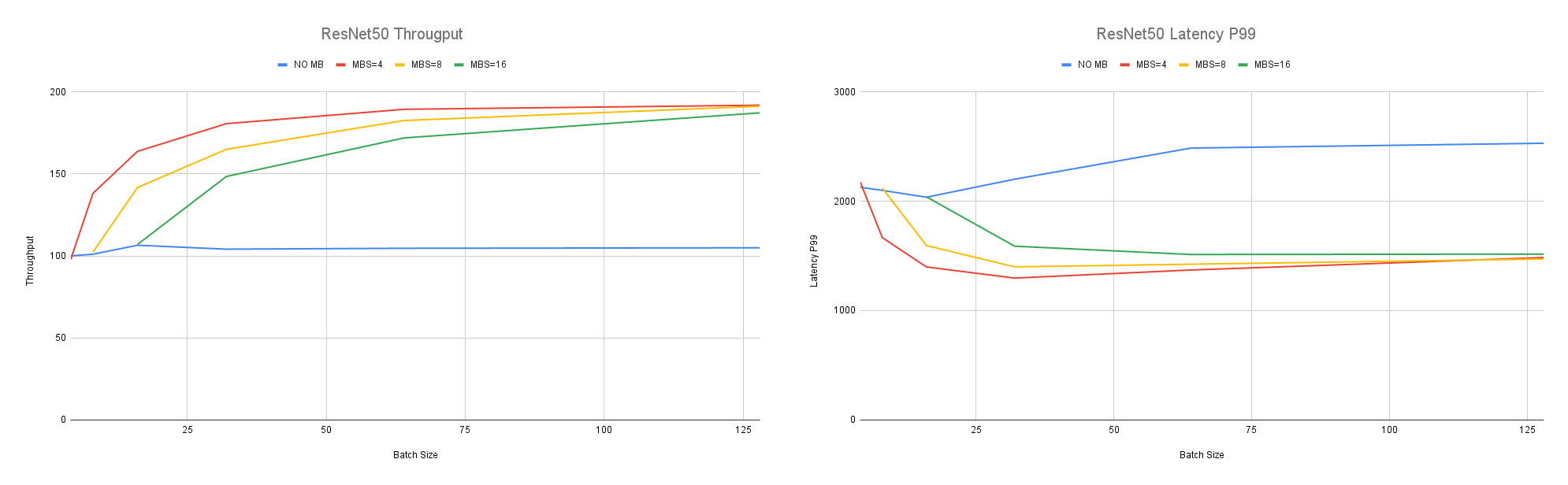
参考评测结果:
Slice & Concat
该机制主要工作在workflow层级
适用场景:
每个request对应的工作负荷较大
比如系统接收的request是时长5s至20s的视频,系统需要对视频的每一帧都要处理,而且前后帧可能需要做关联
此时micros-batching并不能带来吞吐量的提升而且延迟还较大,因为瓶颈点在于request处理本身
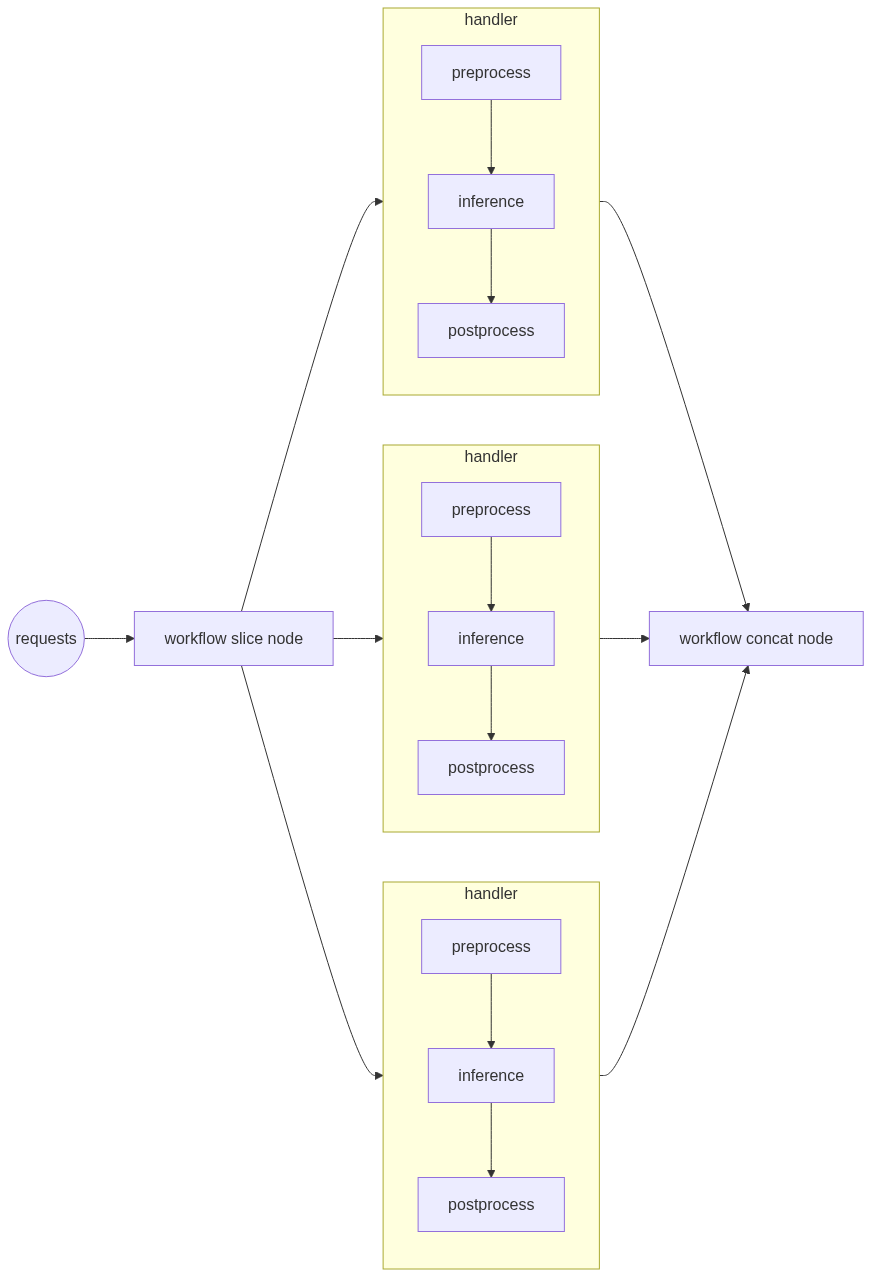
上图所示,对于输入的requests,将其进行拆分,分配到多个Model节点上,各个Model节点独自处理